首先OSPF是工作在IP层的,他需要靠自身的机制去保证报文的可靠性,所以便有了hello报文,定义:
Hello报文是最常用的一种报文,其作用为建立和维护邻接关系,周期性的在使能了OSPF的接口上发送。报文内容包括一些定时器的数值、DR、BDR以及自己已知的邻居。 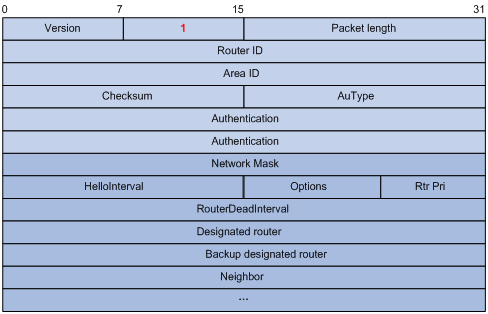
在hello报文中通过 RouterDeadInterval 来验证确定邻居间的故障:
失效时间。如果在此时间内未收到邻居发来的Hello报文,则认为邻居失效。如果相邻两台路由器的失效时间不同,则不能建立邻居关系。
这个参数的计算方式(RouterDeadInterval = 4*HelloInterval),而HelloInterval值是按网络类型设定的,Broadcast和P2P默认是10秒,NBMA默认是30秒,当然这个值是可以手动更改的。
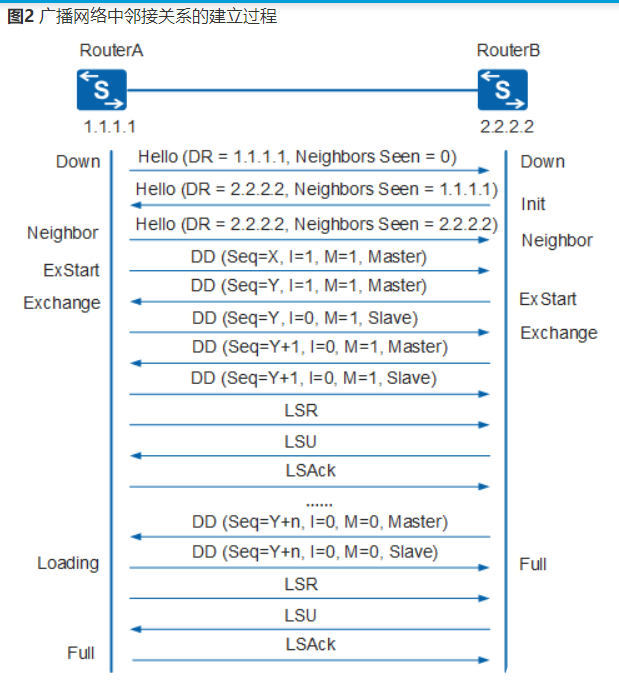
现在假设一台路由某条链路故障,那要在RouterDeadInterval 的时间上再加上该台路由器发送更新LSA至其他路由器,其他路由器再次计算新的路由,这个时间就要看该网络的拓扑大小来判断了。(过程可参考下图)